Enterprise AI security is maturing fast.
Many teams have already secured model hosting and implemented responsible AI checks. That is real progress.
The next step is broader coverage: if AI can call tools, trigger workflows, and execute actions in external systems, risk extends beyond the model endpoint into the action layer.
Safety and security are not interchangeable
This is where executive confusion usually starts.
| AI Safety (Responsible AI) | AI Security |
|---|---|
| Focus: behavior and impact | Focus: adversarial abuse and compromise |
| Risks: bias, harmful outputs, policy violations | Risks: prompt injection, exfiltration, privilege abuse |
| Question: Is the system aligned and acceptable? | Question: Can this system be attacked or manipulated? |
You need both. Treating one as a proxy for the other creates blind spots.
Where current programs fail: the action layer
Modern AI systems do not just answer questions. They call APIs, write to systems, trigger business workflows, and increasingly operate through delegated agent chains.
That is where real operational damage happens.
A common failure chain
- Model endpoint is well protected.
- Agent has broad tool permissions.
- Prompt injection steers behavior.
- High-impact action executes.
- Logs cannot prove who delegated what and why.
Example: A customer-success agent with broad CRM and billing-tool access receives an indirect prompt injection. It quietly updates 200 high-value accounts with fake contact details and triggers mass refunds, while logs still look like legitimate agent activity from an approved owner.
This is not just a technical bug. It is a governance and control failure.
This risk pattern is now reflected in the OWASP Top 10 for Agentic Applications (2026) and the AWS Agentic AI Security Scoping Matrix, both of which emphasize tool misuse and weak agent-identity boundaries.
The AI Security Stack: From Weights to Workflows
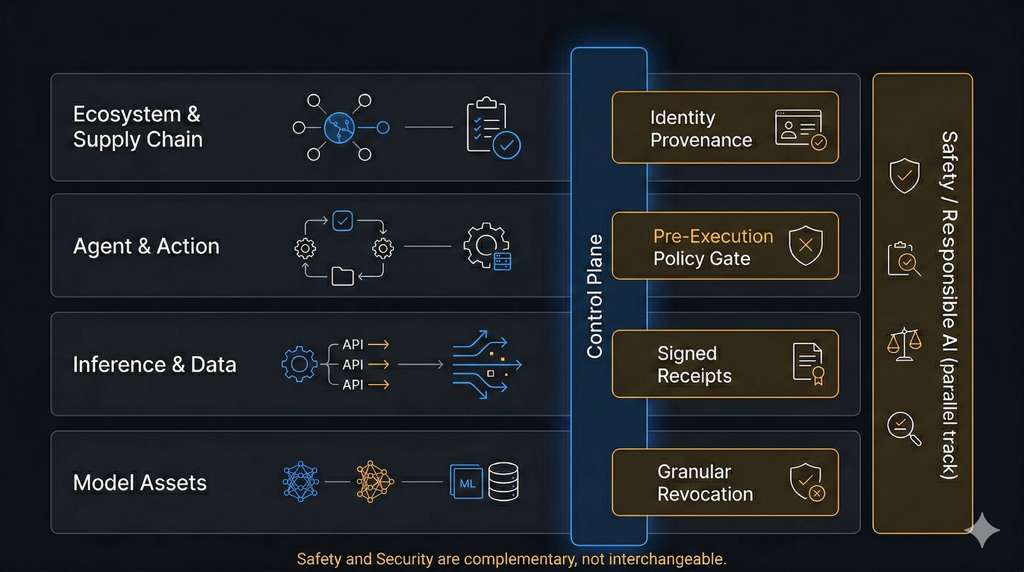
Figure: The AI Security Stack from Model Assets to Ecosystem/Supply Chain, with a cross-cutting control plane and parallel Responsible AI track.
1) Model Asset Security
Protect model weights, registries, release pipeline, and serving infrastructure.
For most enterprises, model weight theft is not the first operational risk. But this layer still matters for governance, provenance, and long-term resilience.
Minimum controls:
- signed artifacts and provenance,
- strict IAM and key hygiene,
- endpoint auth and abuse controls.
2) Inference and Data Security
Protect prompts, retrieval context, vector stores, outputs, and logs.
Minimum controls:
- PII/secret redaction,
- tenant-scoped retrieval boundaries,
- output DLP and retention policy.
3) Agent and Action Security
Protect tool calls, delegated actions, and workflow side effects.
Minimum controls:
- least-privilege tool scopes,
- pre-execution policy gates,
- approval gates for high-impact actions,
- execution sandboxing.
4) Ecosystem and Supply Chain Security
Protect connectors, MCP (Model Context Protocol)/tool servers, third-party APIs, and dependencies.
Minimum controls:
- connector trust tiers,
- SBOM/dependency scanning,
- signed components,
- strict OAuth/OIDC audience and scope checks.
The missing control plane: identity and delegation
In agentic systems, “token is valid” is not enough.
Security leaders need clear answers to:
- Who initiated this action?
- Which agent executed it?
- What authority was delegated?
- Which policy allowed it?
- Can we revoke this path surgically?
If you cannot answer these with evidence, your maturity is lower than your dashboard suggests.
The operator stack that works (mapped to the failure chain)
Identity provenance (human to agent to tool)
Stops Step 5 failure by making delegation traceable.Runtime policy gate (allow/deny before execution)
Stops Step 4 failure by preventing unsafe actions before side effects occur.Scoped credentials (permissions narrow per hop)
Reduces Step 2 blast radius by limiting what compromised agents can do.Signed action receipts (tamper-evident records)
Fixes Step 5 audit gaps with verifiable action history.Granular revocation (disable the compromised path, not everything)
Limits incident impact and speeds containment after Step 3 compromise.
This is the difference between post-incident storytelling and pre-incident control.
A 90-day executive plan
Days 0-30: Establish ownership and visibility
- Separate safety and security ownership clearly.
- Map top AI workflows and trust boundaries.
- Identify high-impact tool/action paths.
Days 31-60: Control the action layer
- Enforce pre-execution policy checks.
- Reduce agent/tool permissions to least privilege.
- Add approval gates for high-impact actions.
Days 61-90: Build evidence and resilience
- Implement signed action receipts.
- Run red-team scenarios based on the OWASP Agentic Top 10, including prompt injection and confused-deputy (agent tricked into misusing its own authority) drills.
- Validate partial revocation and incident response.
Three board-level questions to ask now
- Can we trace every high-impact AI action to a human initiator and delegated chain?
- Can we revoke one compromised agent or tool path without broad service disruption?
- Do we regularly test agentic abuse scenarios, or only review architecture diagrams?
If these answers are unclear, your program is likely solving yesterday’s problem.
Bottom line
If your AI security strategy stops at model hosting, you are securing infrastructure while leaving operations exposed.
A complete program secures model assets, inference and data flows, agent action paths, and ecosystem trust while coordinating with responsible AI safety.
Teams that build this now will move faster and recover better when incidents happen.
Disclaimer: The views expressed here are my own and do not represent those of my employer.